解構 Kubernetes:從 Google 內部專案到雲端原生時代的基石

1. 前言:為何容器編排(Container Orchestration)是現代應用程式的命脈
現代軟體開發與交付的核心趨勢,已明確地轉向以容器(Container)為中心的模式。容器技術將應用程式及其所有執行時期(runtime)與相依套件打包成一個獨立、可執行的映像檔(image),徹底解決了「在我的機器上可以跑」的傳統難題。然而,當我們將這些輕量、可攜的容器部署到正式生產環境時,單純的容器技術反而衍生出新的、更為複雜的管理挑戰。
在正式環境中,應用程式必須滿足一系列嚴苛的要求,這些要求遠遠超出了單一容器自身所能提供的範疇。若缺乏一套系統性的管理機制,維運團隊將很快陷入困境:
- 容錯能力(Fault-tolerance):單一容器或其所在的實體主機可能隨時發生故障。一個獨立的容器無法自我監測或在主機故障時遷移到健康的節點上。
- 彈性擴展(On-demand Scaling):面對突發的流量高峰,應用程式必須能即時、自動地擴展執行個體。單一容器無法自行複製以應對負載,手動介入不僅緩慢,也容易出錯。
- 資源最佳化(Optimal Resource Usage):如何在數百甚至數千個容器間智慧地分配資源?單獨的容器對叢集整體的資源狀況一無所知,無法做出最佳化的排程決策。
- 服務探索與通訊(Service Discovery and Communication):在動態的微服務架構中,容器的 IP 位址是短暫且不可預測的,這使得服務間的可靠通訊成為一大難題。
- 外部存取性(Accessibility from External World):如何將內部執行的服務安全、可靠地暴露給外部使用者?單一容器缺乏內建的穩定端點與流量管理機制。
- 零停機更新與還原(Update/Rollback without Downtime):如何在不中斷服務的前提下發布新版本?直接替換容器必然會造成服務中斷,需要更精密的協調機制。
為了解決上述挑戰,「容器編排」(Container Orchestration)應運而生。它是一套專門設計來管理大規模容器化應用程式的系統,能將多台主機整合為一個統一的資源叢集(Cluster),並自動化處理容器的部署、擴展、管理與網路通訊等複雜任務。
這些盤根錯節的需求共同指向一個結論:我們需要一個更高層次的「作業系統」來管理容器叢集。這正是 Kubernetes 應運而生的舞台,它不僅解決了這些問題,更定義了雲端原生運算的未來。
2. Kubernetes 的崛起:從 Google 的秘密武器到業界標準
Kubernetes,又稱 K8s,是當今容器編排領域的決定性答案。它的起源可追溯至 Google 內部使用了超過十年的秘密武器——Borg 系統。Borg 負責管理 Google 所有服務的容器化工作負載,其寶貴的實戰經驗為 Kubernetes 的設計奠定了堅實基礎。2015 年,Google 將 Kubernetes 專案捐贈給了新成立的雲端原生運算基金會(Cloud Native Computing Foundation, CNCF),使其成為一個由全球社群共同推動的開放原始碼專案。
根據官方定義,Kubernetes 是一個「用於自動化部署、擴展和管理容器化應用程式的開放原始碼系統」。它不僅僅是一個工具,更是一個平台與生態系的基石,為現代應用程式提供了前所未有的彈性與韌性。Kubernetes 的強大之處體現在其豐富的功能集,這些功能直接對應了生產環境中的核心痛點,為開發與維運團隊帶來了巨大的戰略價值。
| 核心功能 (Core Feature) | 對維運的戰略價值 (Strategic Value for Operations) |
|---|---|
| 自我修復 (Self-healing) | 自動取代和重新排程故障節點上的容器,並重新啟動對健康檢查沒有回應的容器。這能大幅提升應用程式的可靠性,並顯著減少人為介入的需求。 |
| 水平擴展 (Horizontal Scaling) | 根據 CPU 和記憶體等資源使用率,自動調整應用程式的執行個體數量。這確保了應用程式在負載變化時能維持效能,同時最佳化成本。 |
| 服務探索與負載平衡 (Service Discovery and Load Balancing) | 將一組容器邏輯上群組化為一個「服務」(Service),並提供單一的 DNS 名稱。K8s 會自動探索這些服務,並在其後端的容器間進行負載平衡,簡化了微服務之間的通訊。 |
| 自動化部署與還原 (Automated Rollouts and Rollbacks) | 以宣告式的方式部署新版本或變更設定,並在過程中確保服務不中斷。若更新出現問題,可快速還原至先前的穩定版本,實現安全的持續交付。 |
| 密鑰與設定管理 (Secrets and Configuration Management) | 將應用程式的設定檔和密鑰(如密碼、API 金鑰)與容器映像檔解耦。這使得應用程式配置更靈活,且能安全地管理敏感資訊,無需重新建置映像檔。 |
| 儲存編排 (Storage Orchestration) | 自動化掛載本地、外部雲端或網路儲存解決方案至容器。開發者只需宣告所需的儲存類型,無需關心底層儲存基礎設施的細節。 |
Kubernetes 的這些強大功能,源自其精密且模組化的架構設計。正是這套架構,為雲端原生應用提供了穩定可靠的運作基礎。
3. 架構藍圖:剖析 Kubernetes 的核心組件
要真正掌握 Kubernetes 的威力,理解其架構至關重要。Kubernetes 採用了經典的主從式(Client-Server)架構模型,由負責管理整個叢集的 主節點(Master Node) 和負責執行實際應用程式工作負載的 工作節點(Worker Node) 組成。這種職責分離的設計,是 Kubernetes 實現高可用性、擴展性和韌性的關鍵。
主節點是 Kubernetes 叢集的控制平面(Control Plane),負責做出所有全局決策,並作為所有管理任務的統一入口。
- API Server:作為 Kubernetes API 的統一入口點,處理並驗證所有來自內部及外部的管理請求。
- Scheduler:根據資源需求與策略限制,智慧地將新建立的 Pod 指派到最適當的工作節點上執行。
- Controller Manager:運行一系列的控制器迴圈,持續比對叢集的期望狀態與實際狀態,並自動採取修正措施以確保兩者一致。
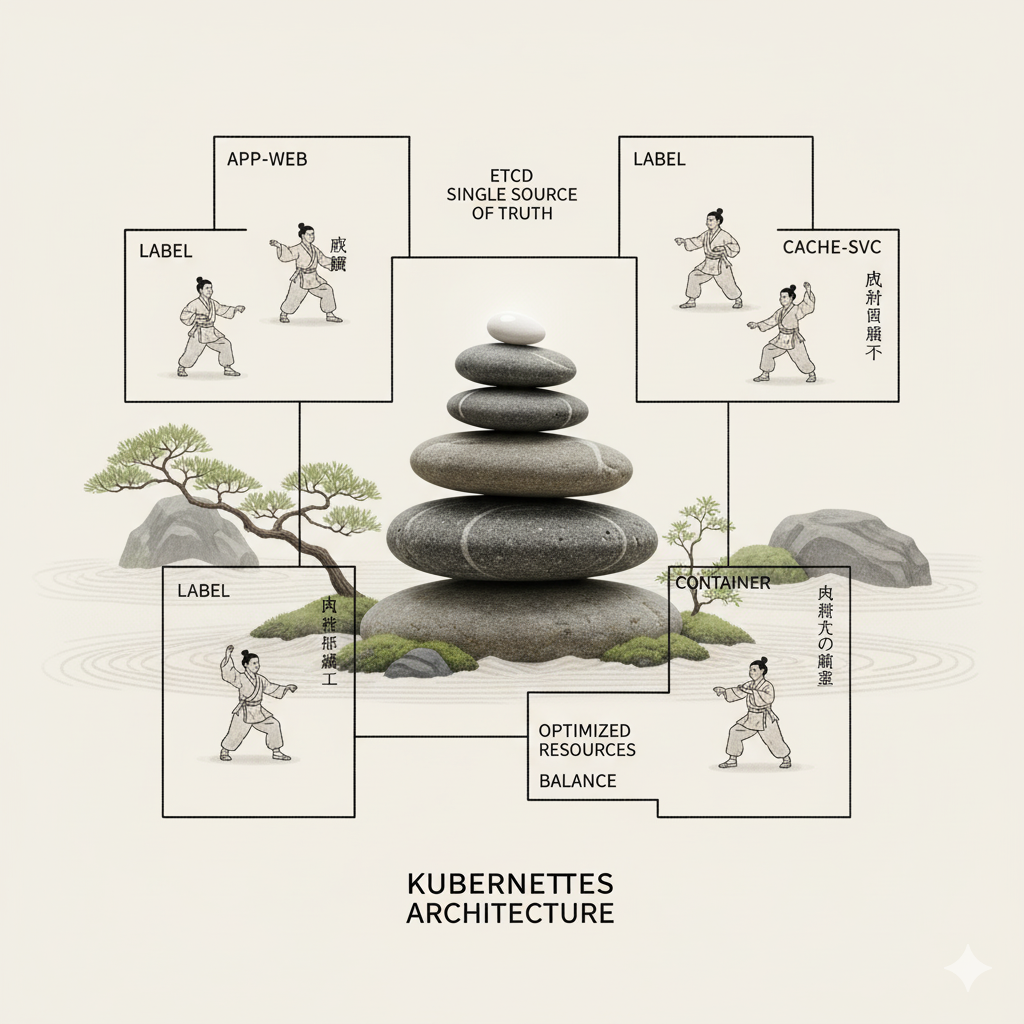
- etcd:作為叢集唯一的真相來源(Single Source of Truth),在一個高可用性的鍵值儲存系統中持久化保存整個 Kubernetes 叢集的狀態資料。
工作節點是叢集中的工作機器,其主要職責是根據主節點的指令,實際運行並管理應用程式容器。
- kubelet:作為運行在每個工作節點上的核心代理程式,負責與主節點通訊,並確保 Pod 中定義的容器處於運行且健康的狀態。
- kube-proxy:負責管理節點上的網路規則,實現 Kubernetes 服務(Service)的網路通訊與負載平衡。
- Container Runtime:負責實際運行容器的底層軟體,例如
containerd,由 kubelet 透過 CRI 介面進行互動。
這套分工明確的架構,為管理 Kubernetes 中的核心資源——也就是應用程式的抽象化物件——提供了穩固的基礎。
4. 核心抽象化:應用程式管理的基石
Kubernetes 的真正強大之處,不僅在於其穩健的架構,更在於它提供了一套豐富的物件模型(Object Model)。開發者可以透過這套模型,以「宣告式」的方式定義應用程式的期望狀態,而 Kubernetes 系統則會自動地將實際狀態調整至與期望狀態一致。接下來,我們將探討其中最基礎且最重要的幾個核心物件:Pods、Deployments 與 Services。
- Pod:是 Kubernetes 中最小、最基本的部署單位。它並非單一容器,而是一個或多個緊密相關容器的邏輯集合。在同一個 Pod 內的容器會共享相同的網路命名空間與儲存空間,是 Kubernetes 進行排程的基礎單元。
- 標籤(Labels)與選擇器(Selectors):標籤是附加到 Kubernetes 物件上的「鍵/值」對,用於組織資源。選擇器則是基於標籤來篩選與選取物件的機制。這是 Kubernetes 中實現資源分組與管理的核心耦合機制。
- ReplicaSet:其核心職責是確保在任何時間點,都有指定數量的 Pod 副本(replicas)正在運行。如果某個 Pod 失效,ReplicaSet 會立刻啟動一個新的 Pod 來取代它,從而實現應用的自我修復。
- Deployment:是一個更高層次的控制器,它負責管理 ReplicaSet 的生命週期。Deployment 的戰略價值在於它實現了對應用程式的「宣告式更新」,能夠自動地、逐步地創建新版副本並轉移流量,從而實現零停機的自動化部署(rollout)與還原(rollback)。
- Service:是一個關鍵的抽象化概念,它為一組功能相同的 Pod 提供了一個穩定、單一的網路端點(包含一個固定的內部 IP 位址和 DNS 名稱)。由於 Pod 本身是短暫的,其 IP 位址會隨重建而改變,Service 完美地解決了這個問題,利用標籤選擇器持續追蹤後端健康的 Pod,實現了叢集內部穩定的服務探索(service discovery)與負載平衡(load balancing)。
這些核心的抽象化物件構成了部署應用的基礎。然而,在真實世界中,應用程式還需要管理外部化的設定、持久化的資料以及來自叢集外部的流量。
5. 進階實務:管理設定、儲存與外部流量
當應用程式從簡單部署走向正式生產環境時,除了核心的工作負載管理,還必須妥善處理三大關鍵議題:將設定與程式碼分離、管理持久性資料,以及控制外部流量的存取。Kubernetes 為此提供了專門的資源物件,包括 ConfigMaps、Secrets、Volumes 和 Ingress。
- ConfigMap:這個物件讓您可以將非敏感的設定資料(例如環境變數、設定檔內容)以鍵值對的形式儲存,並與應用程式的容器映像檔完全解耦,使得您可以在不重新建置映像檔的情況下,靈活地修改應用程式設定。
- Secret:專門用於儲存與管理敏感資訊,例如資料庫密碼或 API 金鑰。雖然 Secret 的使用方式與 ConfigMap 類似,但它提供了更嚴格的存取控制。需要注意的是,預設情況下,Secret 中的資料在 etcd 中僅以 base64 編碼儲存,並非加密,因此保護 etcd 的存取安全至關重要。
- Volume:是將儲存空間掛載到 Pod 中的機制,其生命週期與 Pod 相同,可以在容器重啟之間保存資料。
- PersistentVolume (PV) 與 PersistentVolumeClaim (PVC):這是一套更強大的儲存管理抽象。PersistentVolume (PV) 是由叢集管理員預先配置的儲存資源。而 PersistentVolumeClaim (PVC) 則是開發者發出的儲存「請求」。這種設計將應用程式開發者從底層儲存基礎設施的細節中解放出來。
- Ingress:是管理從叢集外部到內部服務的 HTTP 和 HTTPS 流量的 API 物件。相較於
NodePort或LoadBalancer類型的 Service,Ingress 提供了更為豐富和靈活的 Layer 7 路由功能,例如基於傳入請求的主機名稱(Host-based routing)或 URL 路徑(Path-based routing)將流量轉發到不同的後端服務。
這些進階資源為在 Kubernetes 上運行複雜、有狀態的應用程式提供了必要的工具,而其背後蓬勃發展的生態系統則進一步擴展了它的能力邊界。
6. 結論:一個由社群驅動的強大生態系
從一個 Google 內部的專案,到成為雲端原生運算基金會(CNCF)旗下的基石,Kubernetes 的成功旅程不僅證明了其卓越的技術設計,更彰顯了一個活躍、開放的社群所蘊含的巨大能量。它的成功,是技術實力與社群力量完美結合的典範。
Kubernetes 的核心功能雖然強大,但其真正的潛力是透過周邊生態系工具被完全釋放的。例如,Helm 作為 Kubernetes 的套件管理器,透過「Chart」將複雜應用的安裝、升級與管理流程極大簡化。在生產環境中,監控與日誌是不可或缺的,Prometheus 已成為監控與警報的事實標準,而 Fluentd 則提供了強大、統一的日誌收集能力,它們都是與 Kubernetes 緊密整合的 CNCF 專案。
Kubernetes 的發展由一個全球性的、充滿活力的社群所驅動。這個社群透過多種方式進行協作,例如依據特定主題(如網路、儲存)組成的特別興趣小組(Special Interest Groups, SIGs)、活躍的 Slack 頻道,以及全球最大規模的雲端原生技術盛會 KubeCon。這種分散式、目標導向的治理模式(SIGs)確保了 Kubernetes 能夠在多個技術前線並行演進,同時透過開放的溝通管道快速匯集全球智慧,加速了創新與問題解決的速度。
最終,Kubernetes 之所以能夠成為現代雲端時代的基礎設施標準,不僅是因為它解決了容器編排的複雜技術挑戰,更是因為它建立了一個開放、協作且持續創新的強大生態系。對於任何希望建構與運行具備高韌性、高擴展性現代化應用程式的組織而言,Kubernetes 已經不是一個選項,而是一個不可或缺的平台。
資料來源
Kubernetes 核心概念與基礎建設Kubernetes 進階部署與管理